Was passiert, wenn man aufhört Prompts zu optimieren und anfängt Kontext zu architekturieren
Der Begriff Context Engineering taucht derzeit in nahezu jeder Diskussion über LLM-basierte Systeme auf. Die Grundidee ist einfach: Nicht der Prompt allein bestimmt, wie gut ein Agent arbeitet, sondern der Kontext, den er zum Zeitpunkt der Verarbeitung sieht. Welche Daten werden übergeben, welche Tools stehen zur Verfügung, welches Domänenwissen fließt ein, in welchem Format und zu welchem Zeitpunkt? Diese Fragen rücken in den Mittelpunkt, sobald ein LLM-System über die Komplexität eines einzelnen Chat-Prompts hinauswächst.
In diesem Beitrag beschreiben wir, wie Context Engineering in der Praxis aussieht, am Beispiel einer agentengestützten Support-Pipeline, die eingehende Tickets analysiert, den passenden Bearbeitungsprozess zuordnet, relevante Daten aus einem ERP-System abruft, einen Aktionsplan erstellt und eine Kundenantwort generiert. Die wichtigste Erkenntnis nach fünf Wochen Entwicklung war nicht, wie man bessere Prompts formuliert, sondern wie man den Kontext kontrolliert, den jeder einzelne LLM-Aufruf zu sehen bekommt.
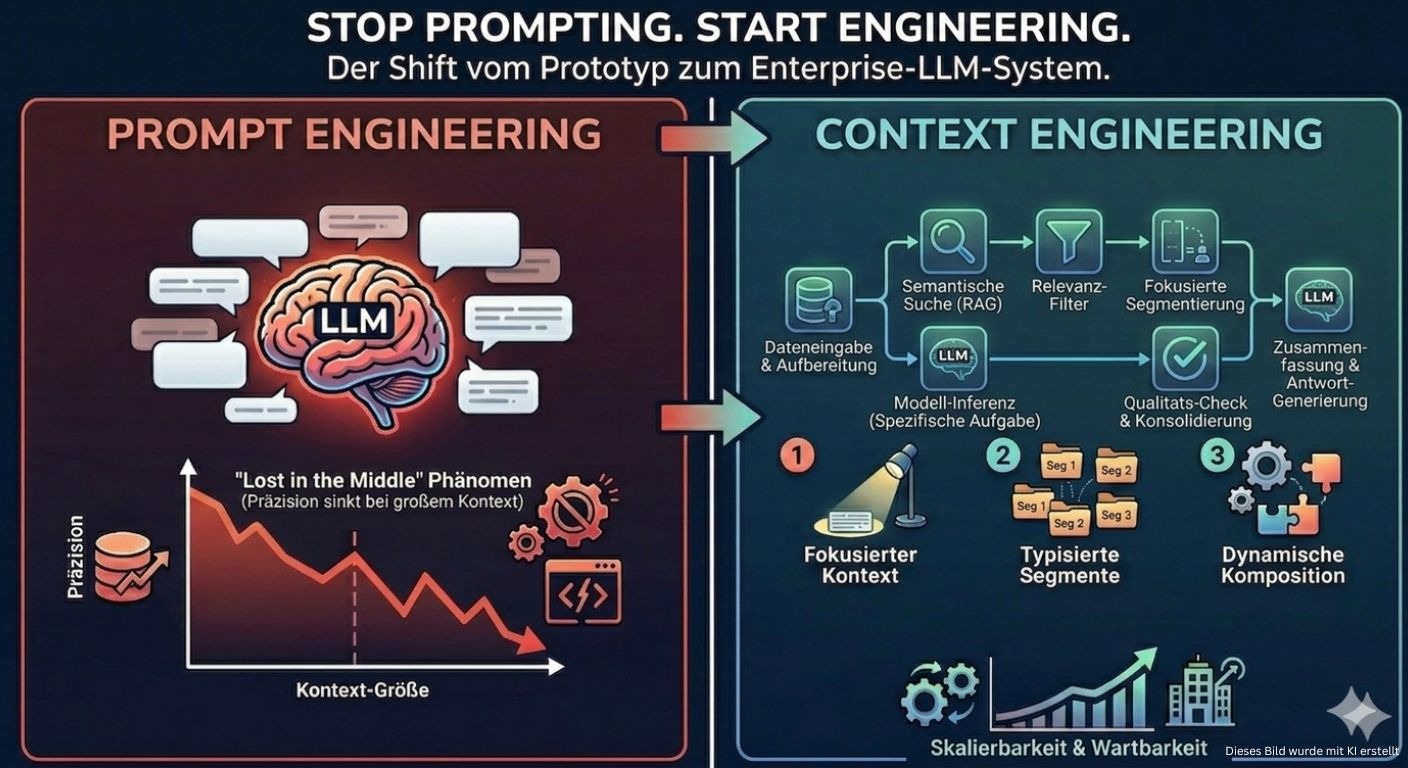
Das Problem mit maximalem Kontext
Der erste Instinkt bei der Arbeit mit großen Sprachmodellen ist nachvollziehbar: Man übergibt dem Modell so viele Informationen wie möglich. Kundendaten, ERP-Einträge, Wissensdatenbank-Artikel, vorherige Analyseergebnisse. Das Context Window moderner Modelle ist groß genug, also hinein damit. Wir haben das so gemacht, und es hat eine Weile funktioniert.
Das Problem zeigt sich schleichend. In der Forschung zu LLM-Verhalten ist dieses Phänomen als Lost in the Middle bekannt: Je mehr Tokens sich im Kontextfenster befinden, desto schlechter wird die Recall-Rate für die tatsächlich relevanten Informationen. Das Modell beginnt, auf irrelevante Details einzugehen oder Informationen gegeneinander abzuwägen, die in keinem fachlichen Zusammenhang stehen. Besonders deutlich wird das, wenn ein einzelner LLM-Aufruf mehrere Aufgaben gleichzeitig erledigen soll. Stimmungsbewertung und Bearbeitungsprozess-Zuordnung im selben Prompt klingt effizient, führt aber dazu, dass das Modell zwischen den Aufgaben priorisieren muss, statt sie sauber voneinander zu trennen.
Dieses Verhalten ist kein Bug, sondern eine inhärente Eigenschaft des Attention-Mechanismus in Transformer-Architekturen. Die Aufmerksamkeit des Modells verteilt sich über alle verfügbaren Tokens, und je mehr davon vorhanden sind, desto stärker wird das Signal-Rausch-Verhältnis verwässert. Die Konsequenz: Mehr Kontext führt ab einem bestimmten Punkt nicht zu mehr Verständnis, sondern zu weniger Präzision.
Pipeline-Architektur mit fokussiertem Kontext
Genau hier setzt die zentrale architektonische Entscheidung unserer Pipeline an. Statt einem monolithischen Prompt, der alles auf einmal verarbeitet, besteht die Pipeline aus zehn spezialisierten Verarbeitungsschritten, davon acht mit LLM-Anbindung, organisiert in sieben Phasen.
Jeder Step hat genau eine Aufgabe. Im ersten Schritt wird das Ticket auf Sicherheitsbedrohungen geprüft. Anschließend laufen drei Steps parallel: Stimmung und Dringlichkeit bewerten, den Kunden im ERP identifizieren und das Ticket gegen die Wissensdatenbank matchen. Keiner dieser drei Steps benötigt das Ergebnis der anderen, also laufen sie gleichzeitig. Danach wird der passende Bearbeitungsprozess zugeordnet, die relevanten Daten aus dem ERP abgerufen und ein Aktionsplan erstellt. Am Ende schreiben Summarizer und Writer parallel die interne Zusammenfassung und die Kundenantwort.
Der entscheidende Aspekt ist nicht die Anzahl der Steps, sondern dass jeder Step seinen eigenen, fokussierten Kontext erhält. Die Sicherheitsprüfung sieht ausschließlich den Ticket-Text. Die Kundenerkennung sieht den Ticket-Text und das ERP. Die Stimmungsanalyse sieht nur den Ticket-Text. Keiner dieser Steps benötigt die Ergebnisse der anderen, und keiner bekommt sie. In der Terminologie des Principle of Least Privilege, das in der Informationssicherheit etabliert ist, erhält jeder Step genau die Informationen, die er für seine Aufgabe benötigt, und nicht mehr.
Typisierte Context-Segmente
Damit eine solche Architektur funktioniert, braucht es eine klare Regelung darüber, wer welche Daten schreiben und lesen darf. In unserer Pipeline schreibt jeder Step seine Ergebnisse in ein eigenes, typisiertes Segment im Pipeline-Context. Das Stimmungs-Segment gehört der Stimmungsanalyse, das Kunden-Segment der Kundenerkennung. Kein Step kann in ein fremdes Segment schreiben.
Dieses Ownership-Modell hat mehrere Vorteile, die sich besonders bei der parallelen Ausführung bemerkbar machen. Erstens: keine Race Conditions. Wenn drei Steps gleichzeitig laufen, schreibt jeder in sein eigenes Segment. Zweitens: keine Schreibkonflikte. Die Datenintegrität ist strukturell garantiert, nicht durch Locking-Mechanismen. Drittens: klare Zurechenbarkeit. Wenn im Kunden-Segment etwas Falsches steht, war es genau ein Step. Diese Zurechenbarkeit ist für das Debugging von LLM-Pipelines von erheblicher Bedeutung, denn eines der größten Probleme in komplexen Multi-Step-Systemen ist die Frage, welcher Verarbeitungsschritt für ein fehlerhaftes Ergebnis verantwortlich ist.
Man kann dieses Konzept als Anwendung des Single Responsibility Principle auf der Datenebene verstehen. So wie in der objektorientierten Programmierung jede Klasse genau eine Verantwortung haben soll, hat in unserer Pipeline jedes Context-Segment genau einen Eigentümer.
Dynamische Kontextkomposition
Am Ende der Pipeline steht der Planner, und der hat ein grundlegend anderes Problem als die frühen Steps. Er muss einen Aktionsplan erstellen, und dafür benötigt er Kontext aus mehreren vorherigen Verarbeitungsschritten. Aber nicht aus allen, und nicht immer denselben.
Ein simples Passwort-Reset braucht drei Datenpunkte im Prompt. Eine Rechnungsreklamation mit mehreren Verträgen braucht zwanzig. Wenn der Planner immer den gesamten verfügbaren Kontext erhält, leidet die Qualität bei den einfachen Fällen, weil das Modell sich in Daten verliert, die für diesen konkreten Fall irrelevant sind. Gleichzeitig fehlen bei komplexen Fällen möglicherweise Informationen, die nicht standardmäßig übergeben werden.
Unsere Lösung für dieses Problem ist die dynamische Kontextkomposition: Der Bearbeitungsprozess selbst deklariert, welchen Kontext er benötigt. Diese Deklaration steht in der Prozesskonfiguration, zusammen mit den ERP-Tools, die aufgerufen werden sollen, und den Fakten, die aus dem Ticket-Text extrahiert werden müssen. Der Planner baut seinen Prompt dynamisch zusammen, basierend auf dem, was der aktive Prozess als relevant markiert hat.
Besonders spannend ist dabei die Konsequenz für die Wartbarkeit. Kein Entwickler pflegt Prompt-Varianten pro Ticket-Typ. Die Prozesskonfiguration ist die Prompt-Konfiguration. Wenn ein neuer Bearbeitungsprozess hinzukommt, definiert er seinen Kontextbedarf deklarativ. Der Planner passt sich automatisch an, ohne dass sein Code oder sein Basis-Prompt geändert werden muss. In der Software-Architektur entspricht dieses Muster dem Open/Closed Principle: Die Pipeline ist offen für Erweiterung durch neue Prozesse, aber geschlossen gegenüber Änderungen an der bestehenden Infrastruktur.
Planung und Ausführung trennen
Das letzte architektonische Puzzlestück betrifft die Trennung zwischen Planung und Ausführung. Der Planner schreibt keine E-Mails. Er erstellt Inhaltsangaben. Welche konkreten Daten in der Kundenantwort stehen müssen, welche Fakten erwähnt werden sollen, welcher Ton angemessen ist, welche Referenznummern oder Vertragsdaten genannt werden müssen.
Der Writer erhält diese Inhaltsangabe plus die Rohdaten, die er referenzieren muss, und verfasst den eigentlichen Text. Der Planner sieht den vollen fachlichen Kontext und destilliert daraus eine fokussierte Anweisung. Der Writer sieht nur diese Anweisung und die Daten, die er benötigt. Zwei fokussierte Prompts statt eines, der alles auf einmal können soll.
Der Planner ist für die fachliche Richtigkeit verantwortlich, der Writer für die sprachliche Qualität. Jeder arbeitet mit genau dem Kontext, den er für seine spezifische Aufgabe braucht. In der Praxis hat sich gezeigt, dass diese Trennung nicht nur die Qualität beider Outputs verbessert, sondern auch das Debugging erheblich vereinfacht. Wenn die Kundenantwort inhaltlich falsch ist, liegt das Problem beim Planner. Wenn sie fachlich korrekt, aber sprachlich unpassend ist, liegt es beim Writer. Diese klare Zurechenbarkeit ist in einer Pipeline mit acht LLM-Aufrufen von unschätzbarem Wert.
Erkenntnisse
Context Engineering ist im Kern eine Architekturfrage. Nicht „wie formuliere ich den Prompt besser“, sondern „welche Informationen sieht das LLM überhaupt, und wer entscheidet das“. In unserer Pipeline haben sich drei Prinzipien als tragend erwiesen:
Ein LLM-Aufruf pro Aufgabe. Jeder Step hat eine klar definierte Verantwortung und erhält genau den Kontext, den er dafür benötigt. Multitask-Prompts, die mehrere Aufgaben in einem Aufruf bündeln, führen ab einer bestimmten Komplexitätsschwelle zu messbaren Qualitätseinbußen. Die Parallelisierung unabhängiger Steps kompensiert den Overhead zusätzlicher LLM-Aufrufe.
Typisierte Ownership über den Context. Jedes Datensegment gehört genau einem Step. Dieses Modell garantiert Datenintegrität bei paralleler Ausführung und ermöglicht eine präzise Fehlerzuordnung. Es überträgt bewährte Prinzipien aus der Software-Architektur, insbesondere Single Responsibility und Data Ownership, auf die Ebene der LLM-Pipeline.
Die Fachlogik entscheidet, was der Prompt enthält. Nicht der Entwickler pflegt Prompt-Varianten, sondern die Prozesskonfiguration deklariert ihren Kontextbedarf. Damit wird die Pipeline erweiterbar, ohne dass bestehender Code oder bestehende Prompts angepasst werden müssen.
Diese drei Prinzipien waren die Konsequenz aus konkreten Problemen, die sich erst gezeigt haben, als die Pipeline gewachsen ist. Sie lassen sich auf einen gemeinsamen Nenner bringen: Kontext ist kein Input, den man maximiert. Kontext ist eine Architekturentscheidung, die man bewusst gestaltet. Wer diesen Perspektivwechsel vollzieht, vom Prompt Engineering zum Context Engineering, baut LLM-Systeme, die nicht nur funktionieren, sondern auch wartbar, debugbar und erweiterbar sind.