
Die Landschaft der künstlichen Intelligenz hat in den letzten Jahren eine bemerkenswerte Transformation durchlaufen. Was einst massive Rechenzentren und spezialisierte Teams erforderte, wird nun für Unternehmen und einzelne Entwickler gleichermaßen zunehmend zugänglich. KI ist zu einem entscheidenden Bestandteil vieler Anwendungen geworden, und das Self-Hosting von KI-Modellen kann größere Kontrolle, Datenschutz und Anpassungsmöglichkeiten bieten, die cloud-basierte Lösungen einfach nicht erreichen können.
Wenn Sie mit sensiblen Daten arbeiten oder spezifische Compliance-Anforderungen haben, wirft das Versenden von Informationen an externe KI-Dienste berechtigte Bedenken hinsichtlich Datensouveränität und Datenschutz auf. Self-Hosting beseitigt diese Sorgen vollständig und gibt Ihnen gleichzeitig die vollständige Kontrolle über Modellauswahl, Feinabstimmung und Leistungsoptimierung.
Deshalb zeigen wir Ihnen in diesem Blogartikel, wie wir bei Fischer & Consultants GmbH KI-Modelle selbst hosten, indem wir Open-Source-Tools und -Frameworks verwenden, und wie Sie diesen Ansatz in Ihrer eigenen Umgebung replizieren können. Wir haben festgestellt, dass dieses Setup sowohl kosteneffizient als auch überraschend unkompliziert zu implementieren ist.
Demo-Hardware-Setup: Das Fundament errichten
Für diese Demonstration führe ich Sie durch das Setup auf einem Linux-Rechner, da dies am wahrscheinlichsten in einer Produktionsumgebung anzutreffen ist. Linux bietet überlegene Stabilität, Ressourcenverwaltung und Kompatibilität mit KI-Frameworks. Der Installationsprozess für Windows und macOS unterscheidet sich – dort werden Installer verwendet, die von der ollama website heruntergeladen werden können, anstelle eines Installer-Skripts.
Für Demonstrationszwecke habe ich eine virtuelle Maschine erstellt, auf der Ubuntu Server 24.04.2 LTS läuft, ausgestattet mit einer NVIDIA GTX 1070 GPU, 12 GB RAM und 4 vCPUs. Dies stellt ein recht bescheidenes Setup dar, das viele Organisationen bereits verfügbar haben oder problemlos bereitstellen können. Das Schöne an dieser Konfiguration ist, dass sie eine Balance zwischen Leistungsfähigkeit und Zugänglichkeit schafft – Sie benötigen keine Hardware auf Enterprise-Niveau, um mit aussagekräftigenKI-Workloads zu beginnen.
Nun, lassen Sie uns den Elefanten im Raum ansprechen: Hardware-Anforderungen. Während es technisch möglich ist, KI-Modelle allein auf einer CPU laufen zu lassen, ist der Leistungsunterschied dramatisch. Wir sprechen hier von dem Unterschied zwischen Minuten versus Sekunden Wartezeit auf Antworten. Und um ganz ehrlich zu sein, ist die ausschließliche Verwendung einer CPU für die meisten praktischen KI-Modelle keine wirklich praktikable Option, besonders wenn Sie mit größeren Sprachmodellen arbeiten, mit denen Ihre Nutzer tatsächlich interagieren möchten. Über die bloße Verfügbarkeit einer GPU hinaus spielt die Menge an VRAM eine bedeutende Rolle – die 8 GB unserer GTX 1070 können kleinere Modelle problemlos bewältigen, aber größere Modelle erfordern GPUs mit 16 GB+ wie die RTX 4080 oder professionelle Karten wie die A6000. Speicherbandbreite, CUDA-Kerne und sogar die PCIe-Slot-Konfiguration beeinflussen alle die Leistung, wobei neuere Architekturen wesentlich bessere Token-pro-Sekunde-Raten liefern.
Die bevorzugte Wahl für viele Organisationen sind NVIDIA-GPUs, und es gibt gute Gründe für diese Präferenz. Sie sind zum De-facto-Standard in der Branche geworden und bieten außergewöhnliche Unterstützung für KI-Workloads durch CUDA-Beschleunigung. Das Ökosystem rund um NVIDIA-Hardware ist ausgereift, gut dokumentiert und wird aktiv gepflegt, was sich in weniger Kopfschmerzen sowohl während des Setups als auch im laufenden Betrieb niederschlägt.
Ollama installieren und Ihren ersten Prompt schreiben
Hier wird es spannend – und überraschend einfach. Das Einrichten von ollama ist absolut trivial geworden, was eine erfrischende Abwechslung zu den komplexen KI-Infrastruktur-Deployments von vor wenigen Jahren darstellt. Das ollama-Team hat außergewöhnliche Arbeit geleistet, um das, was früher ein mehrtägiger Setup-Prozess war, in etwas zu verwandeln, das Sie während einer Kaffeepause erledigen können. Was ollama besonders beeindruckend macht, ist, dass es ein intelligentes Installer-Skript bereitstellt, das nicht nur die ollama-Installation selbst übernimmt, sondern sich auch um die Installation der NVIDIA-Treiber und des CUDA-Toolkits kümmert, wenn es eine NVIDIA-GPU auf Ihrem System erkennt. Dieser Grad an Automatisierung eliminiert die meisten traditionellen Schmerzpunkte, die früher das Setup von KI-Infrastrukturen plagten.
Dieser einfache Befehl von der ollama download Seite übernimmt den gesamten Installationsprozess für Sie:
curl -fsSL https://ollama.com/install.sh | sh
Die Ausgabe sollte ungefähr so aussehen:
fc@ai-tutorial:~$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for fc:
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> Installing NVIDIA repository...
>>> Installing CUDA driver...
Selecting previously unselected package cuda-keyring.
(Reading database ... 86812 files and directories currently installed.)
Preparing to unpack .../cuda-keyring.deb ...
Unpacking cuda-keyring (1.1-1) ...
Setting up cuda-keyring (1.1-1) ...
Hit:1 http://de.archive.ubuntu.com/ubuntu noble InRelease
Get:2 http://de.archive.ubuntu.com/ubuntu noble-updates InRelease [126 kB]
....
Achten Sie besonders auf diese beiden kritischen Zeilen in der Ausgabe:
>>> Installing NVIDIA repository...
>>> Installing CUDA driver...
Diese Zeilen bestätigen, dass ollama Ihre NVIDIA-GPU erfolgreich erkannt hat und sich darum kümmert, alle notwendigen Abhängigkeiten zu installieren, um die GPU-Beschleunigung zu nutzen. Dieser automatisierte Erkennungs- und Setup-Prozess erspart Ihnen die manuelle Konfiguration der CUDA-Treiber, was historisch gesehen einer der frustrierenderen Aspekte beim Einrichten von KI-Infrastruktur war. Um zu überprüfen, dass ollama korrekt installiert wurde und einsatzbereit ist, können Sie den einfachen Befehl
ollama
Befehl, der die Hilfemeldung ausgibt:
fc@ai-tutorial:~$ ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
Nun kommt der Moment der Wahrheit – Ihren ersten KI-Prompt lokal ausführen. Sie können dies mit einem einfachen Befehl erreichen:
ollama run llama3.2
Dieser Befehl löst im Hintergrund mehrere Vorgänge aus. Zunächst wird automatisch das llama 3.2-Modell heruntergeladen, falls Sie es nicht bereits lokal gecacht haben. Abhängig von Ihrer Internetverbindung kann dieser erste Download einige Minuten dauern, aber nachfolgende Durchläufe werden nahezu augenblicklich sein, da das Modell lokal gespeichert ist. Sobald das Modell in den Speicher geladen ist, gelangen Sie zu einem interaktiven Prompt, in dem Sie Ihren Text eingeben und Antworten direkt vom Modell erhalten können, das auf Ihrer eigenen Hardware läuft. Es ist zutiefst befriedigend, diese ersten Antworten lokal generiert zu sehen, anstatt dass sie irgendwo in einem entfernten Rechenzentrum verarbeitet werden.
fc@ai-tutorial:~$ ollama run llama3.2
>>> hello
Hello! How can I assist you today?
Herzlichen Glückwunsch! Sie haben gerade Ihren ersten KI-Prompt auf Ihrer eigenen Infrastruktur ausgeführt. Dies stellt einen bedeutenden Meilenstein dar – Sie haben nun ein voll funktionsfähiges, lokal gehostetes KI-System, das echte Workloads ohne externe Abhängigkeiten oder Datenschutzbedenken bewältigen kann. Wenn Sie bereit sind, die interaktive Sitzung zu beenden, drücken Sie einfach Ctrl+D und nehmen Sie sich einen Moment Zeit, um zu würdigen, was Sie erreicht haben. Sie haben erfolgreich Ihre erste selbst gehostete KI-Umgebung eingerichtet und sind der wachsenden Gemeinschaft von Organisationen beigetreten, die die Kontrolle über ihre KI-Infrastruktur übernehmen.
Die Wahl des richtigen Modells: Navigation durch die KI-Landschaft
Nun, da Sie ollama am Laufen haben, ist die nächste entscheidende Entscheidung die Auswahl des richtigen Modells für Ihre spezifischen Anforderungen. Das Durchsuchen der ollama model Modellbibliothek offenbart eine beeindruckende und etwas überwältigende Auswahl an Modellen, die jeweils für verschiedene Anwendungsfälle und Leistungsmerkmale optimiert sind. Die Vielfalt hier ist tatsächlich einer der Hauptvorteile des Self-Hostings – Sie sind nicht an die Modellangebote eines einzelnen Anbieters gebunden. Diese Modelle decken ein breites Spektrum an Spezialisierungen ab: Einige zeichnen sich bei allgemeiner Textgenerierung und Konversation aus, andere sind für Code-Vervollständigung und Programmieraufgaben feinabgestimmt, während sich wieder andere auf spezifische Bereiche wie wissenschaftliches Schreiben oder die Erstellung kreativer Inhalte konzentrieren.
Das Verständnis der Namenskonventionen und Tags wird für fundierte Entscheidungen unerlässlich. Attribute wie [irgendeine Zahl]b (das Milliarden von Parametern anzeigt) geben Ihnen sofortigen Einblick in die Komplexität und Ressourcenanforderungen des Modells – im Allgemeinen korrelieren mehr Parameter mit besseren Ergebnissen, aber auch mit höherem Speicherverbrauch und langsameren Inferenzzeiten. Tags wie tools, embedding, thinking oder vision bieten beim Durchsuchen der Bibliothek einen schnellen Überblick über die spezialisierten Fähigkeiten des Modells und helfen Ihnen, Modelle zu identifizieren, die mit Ihren beabsichtigten Anwendungsfällen übereinstimmen. Hier ist ein Beispiel:
Dieses spezielle Modell heißt llama3.2 und demonstriert die Flexibilität moderner KI-Modellverteilung. Es ist in mehreren Größen verfügbar – 1-Milliarden- und 3-Milliarden-Parameter-Versionen (1b und 3b) – sodass Sie basierend auf Ihren Hardware-Einschränkungen und Leistungsanforderungen wählen können. Der tools-Tag zeigt an, dass dieses Modell darauf trainiert wurde, mit Funktionsaufrufen und externer Tool-Integration zu arbeiten, was es besonders wertvoll für die Entwicklung KI-gestützter Anwendungen macht, nicht nur für Konversationsschnittstellen. Wenn Sie zur Detailseite durchklicken, indem Sie den Modellnamen auswählen, entdecken Sie wesentlich umfassendere Informationen über die Fähigkeiten und Anforderungen des Modells. Die Größe in GB ist besonders kritische Information, da diese direkt bestimmt, ob das Modell realistischerweise auf Ihrer verfügbaren Hardware laufen kann. Es macht keinen Sinn, sich über ein hochmodernes Modell zu freuen, nur um dann festzustellen, dass es mehr VRAM benötigt, als Ihr System zur Verfügung hat.
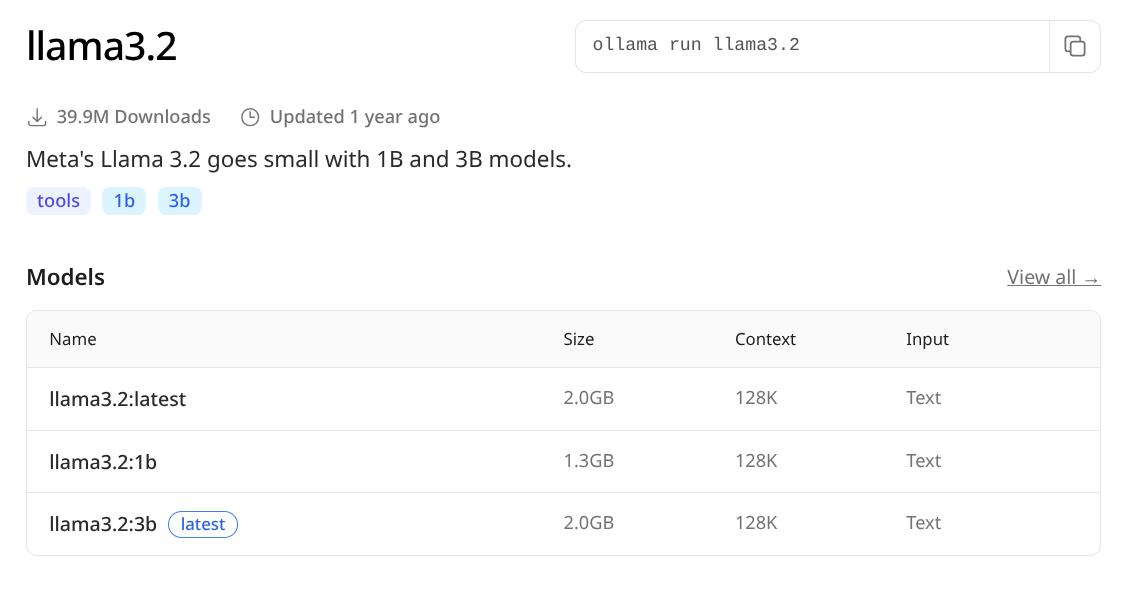
Wenn Sie speziell die kleinere, ressourceneffizientere Version von llama3.2 ausführen möchten, können Sie sie direkt anvisieren, indem Sie den vorherigen Befehl modifizieren:
ollama run llama3.2:1b
Diese explizite Versionierung gibt Ihnen präzise Kontrolle darüber, mit welcher Modellvariante Sie arbeiten, und ermöglicht es Ihnen, entweder für Leistung oder Ressourcennutzung zu optimieren, basierend auf Ihren aktuellen Anforderungen. Der wirkliche Wert liegt im Experimentieren. Sie können problemlos mit verschiedenen Modellen herumspielen, ihre Antworten, Geschwindigkeit und Ressourcennutzung vergleichen, um zu bestimmen, welches für Ihren spezifischen Anwendungsfall am besten funktioniert. Einige Modelle zeichnen sich beim kreativen Schreiben aus, andere bei technischer Dokumentation und wieder andere bei der Code-Generierung. Das Schöne am Self-Hosting ist, dass Sie nahezu augenblicklich zwischen ihnen wechseln können, ohne externe Abhängigkeiten oder API-Ratenlimits.
Weiterführende Informationen
Mit diesem Fundament sollten Sie gut gerüstet sein, um mit dem Self-Hosting von KI-Modellen auf Ihrer eigenen Hardware zu beginnen. Sie haben gelernt, wie Sie die Infrastruktur einrichten, geeignete Modelle auswählen und direkt mit ihnen interagieren. Dies gibt Ihnen eine solide Basis für die Entwicklung anspruchsvollerer KI-gestützter Anwendungen oder die Integration lokaler KI-Fähigkeiten in bestehende Systeme.
Die Reise muss hier jedoch nicht enden. Self-gehostete KI eröffnet Möglichkeiten zur Feinabstimmung von Modellen auf Ihre spezifischen Daten, zur Entwicklung maßgeschneiderter Anwendungen, die mehrere Modelle nutzen, oder zur Erstellung von KI-Workflows, die vollständigen Datenschutz wahren. Die Infrastruktur, die Sie heute eingerichtet haben, kann skalieren, um wesentlich komplexere Anwendungsfälle zu unterstützen, während Ihre Anforderungen wachsen. Wenn Organisationen ihre KI-Implementierungen über diese Grundlagen hinaus skalieren, werden Überlegungen zu Load Balancing, Modell-Orchestrierung und Enterprise-Sicherheit zunehmend wichtig.
Bei Fischer & Consultants GmbH arbeiten wir mit Unternehmen zusammen, die diese komplexeren Deployments und maßgeschneiderten KI-Integrationen navigieren. Wenn Sie Implementierungen auf Enterprise-Ebene erkunden, können Sie sich gerne melden, um Ihre spezifischen Anforderungen zu besprechen.