
Von Code zu Code : Ein Überblick
Nachdem wir dafür gesorgt haben, dass auf unserem Zielsystem eine strukturgleiche Datenbank existiert und diese auch mit Daten gefüllt ist, kümmern wir uns im Folgenden darum, die noch fehlenden Entitäten
- Views
- Functions
- Procedures
- Trigger vorzubereiten und zu generieren (wir sprechen hier gerne vom Transpilieren, also von der Überführung einer Sprache in eine andere).
Warum ist das notwendig? SQL ist doch SQL, oder etwa nicht?
Definitiv nicht! Es gibt zwar eine Norm des ANSI-Komitees, die die Hersteller auch implementieren, aber es gibt durchaus große Unterschiede in der Umsetzung. Oft beschreiten die Hersteller gerne ihre eigenen Wege und bieten dem Anwender syntaktischen wie auch funktionalen „Zucker“ an. Gerade SQL Anywhere zeichnet sich hier durch allerlei Spezialitäten aus, die das Leben des SQL-Programmierers vereinfachen. Man erkauft sich diese Erleichterungen jedoch durch Inkompatibilitäten und hat es entsprechend schwer, wenn es darum geht, seinen Code auf ein anderes System zu portieren.
Welche Techniken stehen uns zur Verfügung?
- Verwendung von am Markt angebotenen Tools
- Manuelles Übersetzen
- Regelwerk auf Basis von regulären Ausdrücken oder ähnlichen Techniken
- Ausgehend von einer Grammatik mit passendem Parser automatische Generierung über eigene Komponenten
- Source-Generierung über KI
Verwendung externer Tools
Wir haben uns auf dem Markt umgesehen und einige Tools ausprobiert. Was alle Tools recht gut hinbekommen haben, ist die Übernahme des Schemas und der Daten. Aber bei der Übernahme von Code-Entitäten tun sich alle schwer. Einige funktionierten gar nicht, andere nur zum Teil, wieder andere boten nur bestimmte Zielplattformen. Alles in allem war das größtenteils Zeitverschwendung.
Manuelles Übersetzen
Ist die Datenbank nicht allzu groß und der Anteil an SQL-Programmierung eher übersichtlich, dann ist dies tatsächlich eine Option, vorausgesetzt, man verfügt über ausreichende interne oder externe Kapazitäten. In Anbetracht der Tatsache, dass viele Datenbanken schon ein paar Jährchen auf dem Buckel haben und der Code durchaus durch viele Hände gegangen ist, bietet dieses Vorgehen durchaus auch Chancen. Wenn das nötige Know-how noch im Hause vorhanden ist, kann ein Refactoring auch inhaltlich sehr vorteilhaft sein. Bei größeren Datenbanken lohnt sich dies jedoch nicht, da es viel zu viel Zeit beanspruchen würde.
Regelwerk auf Basis von regulären Ausdrücken oder ähnlichen Techniken
Für Teilaufgaben kann dies eine durchaus geeignete Vereinfachung sein. So könnte man durchaus über solche Regeln bestimmte Teile im Sourcecode ersetzen. Leider hilft dieser Weg wenig, da keine logischen Zusammenhänge erkannt werden. Wir wissen im Voraus bereits, dass wir den Code auch neu anordnen müssen, und dafür ist diese Technik wenig geeignet.
Ausgehend von einer Grammatik mit passendem Parser: Automatische Generierung über eigene Komponenten
Nehmen wir an, wir würden über eine Grammatik für ASA SQL verfügen und könnten diese zur Grundlage eines Parsers machen. Dann wären wir in der Lage, jeden beliebigen, gültigen ASA-Code zu analysieren und in einen Abstract Syntax Tree (AST) zu übersetzen. Diesen könnten wir dann nutzen, um Code für das Zielsystem zu generieren. Das Hauptproblem: Wo bekommt man eine solche Grammatik her? Die Hersteller veröffentlichen natürlich nicht so ohne Weiteres die Grundlage für ihre internen Parser (die sie ja brauchen, um Befehle umzusetzen). Immerhin findet man im Netz durchaus umfangreiche Grammatik-Definitionen für die gängigen Standards (ANSI 2003). Ausgehend von einer solchen Grammatik haben wir eine für SQL Anywhere entwickelt. Das hat uns in die Lage versetzt, unseren eigenen Parser zu generieren. Dieser Parser macht im Übrigen auch Gebrauch von den Techniken aus Punkt 2.
Source Generierung über KI
Erzeugen von Texten? Da war doch was … seit ca. 1,5 Jahren in aller Munde: AI oder KI. Könnte man nicht einfach den zu übersetzenden Text nehmen, in eine KI stecken und den fürs Zielsystem gültigen Code frei Haus geliefert bekommen? Erste Versuche waren recht vielversprechend … wir werden sehen, warum das als alleiniger Ansatz nicht reicht. Immerhin könnten wir die Antworten der KI als Anregung und Wegweiser durchaus sehr gut nutzen.
Resümee
Welche Vorgehensweise wählen wir denn jetzt? Kurz gesagt: Alle außer Punkt 1, denn wir schreiben unser eigenes Tool. Dort, wo wir können, greifen wir auf unseren Parser und den AST zurück. Manchmal kommt es vor, dass ein manuelles Überarbeiten einfacher ist, z.B. weil ein bestimmtes Problem nur einmal auftaucht, dann bemühen wir Punkt 2. In allen anderen Fällen lassen wir uns von der KI inspirieren und beschreiten diesen Weg. Prinzipiell ist die Vorgehensweise bei allen Entitätstypen gleich. Wir beschränken uns daher in diesem Rahmen auf die vermeintlich einfachste Form: Die Views.
Von Code zu Code : Parsen und die Folgen
In diesem Abschnitt geht es darum, die Grundlage zu erläutern, wie man, ausgehend von einer Grammatik, SQL Anywhere Code analysiert und in einen Abstract Syntax Tree (AST) überführt. Diesen AST werden wir dann im Weiteren nutzen, um den Eingangscode zu manipulieren, damit wir am Ende Code erhalten, der auf MSSQL ausgeführt werden kann.
In diesem Abschnitt demonstrieren wir, wie wir den Parser und den AST einsetzen können, um gezielt Code für MSSQL zu generieren. Die vorgestellten Techniken sind natürlich auch zu gebrauchen, um Code für andere DBMS zu erzeugen.
Vorbereitungen
Es empfiehlt sich, vor einer weiteren Bearbeitung einzelner Entitäten, alle zuvor exportierten Code-Files durch den Parser zu schicken. Werden diese erfolgreich geparst, verschieben wir sie in das Unterverzeichnis „prepared“. Die Entitäten, die nicht geparst werden können, verbleiben im Code-Verzeichnis. Diese müssen wir analysieren und ggf. in der ASA fixen. Bei der Arbeit mit verschiedenen DBs kam es immer mal wieder vor, dass wir diese nicht parsen konnten. Dafür gibt es verschiedene Gründe; die häufigsten sind:
- Verwendung von illegalen Zeichen
- Kommentare, die nicht der Grammatik entsprechen
Bei Letzterem ist die ASA sehr tolerant und lässt vieles durchgehen. Wir müssen hier aber auf unserer Grammatik pochen. Sind wir mit diesem Schritt durch, können wir uns der Code-Generierung widmen.
Das Visitor Pattern
Visitoren spielen im Weiteren eine entscheidende Rolle. Im Zusammenspiel mit den Klassen der Knoten im AST implementieren sie das sogenannte Visitor Pattern. Hierbei handelt es sich um ein Entwurfsmuster, das zur Durchführung von Operationen auf komplexen Strukturen verwendet wird. Der Algorithmus wird also von der Objektstruktur entkoppelt und eignet sich hervorragend für unsere kommenden Aufgaben. In den Basisbibliotheken ist ein Basis-Visitor vordefiniert, der allerdings keinerlei Funktionalität trägt, sondern uns lediglich das Leben erleichtern soll, um eigene Visitoren zu entwickeln.
Benötigte Resourcen
Für unser eigenes Tooling haben wir NuGet-Pakete entwickelt, auf die wir im Folgenden zurückgreifen. Immer wenn Sie auf eine using-Anweisung stoßen, die mit AppFact. beginnt, gehen Sie davon aus, dass es ein dazu passendes NuGet-Paket gibt.
SQL-Code parsen
Im nachfolgenden Beispiel parsen wir ein einfaches SELECT-Statement und nutzen den resultierenden Abstract Syntax Tree (AST), um das Eingabe-Statement wieder auszugeben, allerdings bereinigt um jeglichen Whitespace (Zeilenvorschübe, überflüssige Leerzeichen, Kommentare etc.).
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa;
using Migrate.Common.Helper;
var parserAsa = new SqlAnsi2003QueryGrammarAsaParser();
string sqlCode ="""
select a
,b
,current date as c
from dummy
where 1=1
""";
var isParsed = parserAsa.Parse(ref sqlCode);
Console.WriteLine(parserAsa.AST().Source())
Hier das Ergebnis:
select a , b , current date as c from dummy where 1 = 1
Wie man sieht, sind alle Whitespaces entfernt. Wir haben an dieser Stelle auch implizit eine sehr wichtige Erweiterungsmethode (Source()) kennengelernt. Diese Methode erzeugt aus einem beliebigen Knoten des AST den zugehörigen Sourcecode. Eine Funktionalität, die im Folgenden sehr wichtig wird.
Sidestep: Visualisierung mit Mermaid
Zu Demonstrationszwecken verfügen unsere Bibliotheken über einen Visitor, der aus dem AST eine Graphendefinition für Mermaid erzeugt. (Wir setzen für Vortragzwecke Polyglot Notebooks ein, Mermaid ist dort direkt integriert.) So führt folgender Code zu dem Graphen des AST:
using AppFact.GoldParser.Interfaces.Interfaces;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa;
using AppFact.GoldParser.Engine;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.VisitorInterface;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Visitor;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Grammar;
using Microsoft.DotNet.Interactive.Mermaid;
var visitor = new SqlAnsi2003QueryGrammarAsaParserMermaidVisitor();
parserAsa.AST().Accept(visitor);
var code = visitor.TokenList.ToString();
new MermaidMarkdown(code)Hier ein Teil der Ausgabe:
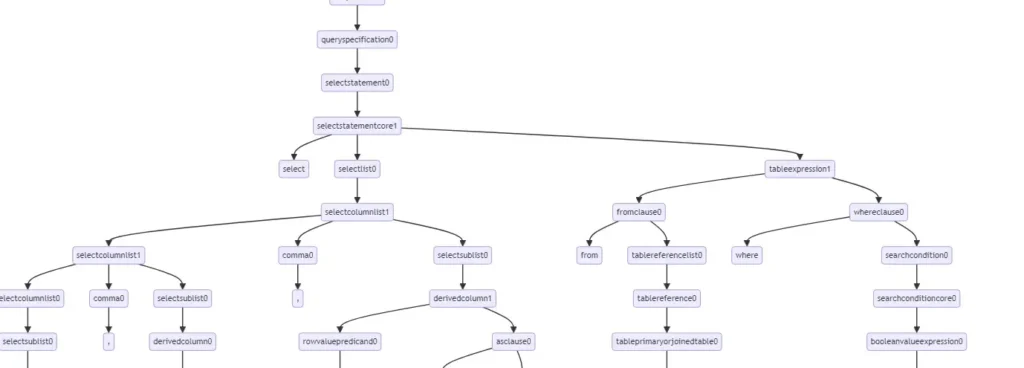
Wie man sieht, wird der AST visualisiert. Bei den Teilen, die nur einzelne Nachfolgeknoten haben, spricht man von degenerierten Bäumen. Diese ließen sich über den Parser unterdrücken (TrimReductions), aber in unserem Fall geht das nicht, da die Knoten alle streng typisiert sind und daher keine Polymorphie zulassen. Wie wir später noch sehen werden, ist das auch ganz gut so, weil wir gezielt Manipulationen im Baum vornehmen können. Leider werden solche Graphen recht groß, sodass sie in der Praxis recht schwerfällig sind. Aber zum besseren Verständnis sind sie dennoch sehr hilfreich.
Visitoren & Knoten
Im obigen Graphen sehen wir als Knotenbezeichnungen immer die Namen der Klassen, die den jeweiligen Knoten repräsentieren. Bei Knoten ohne Nachfolger (Blätter) sprechen wir von Tokens. Diese sind sozusagen atomar und stellen den Eingabetext dar. Knoten mit Nachfolger(n) repräsentieren sogenannte Reduktionen, die Syntaxregeln der Eingabesprache (Grammatik).
Die Tokens haben einen Accessor, mit dem wir den ursprünglichen Eingabetext zurückgewinnen können. Eine Aufgabe, die uns im Folgenden häufiger begegnen wird. Lassen Sie uns einen Visitor schreiben, der genau dies tut: Aus einem AST (es kann auch ein Teilabschnitt sein) Sourcecode generiert.
using AppFact.GoldParser.Interfaces.Interfaces;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa;
using AppFact.GoldParser.Engine;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.VisitorInterface;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Visitor;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Grammar;
public class SourceCodeVisitorLocal : SqlAnsi2003QueryGrammarAsaParserVisitor
{
private readonly StringBuilder sb = new StringBuilder();
public string Source
{
get { return sb.ToString(); }
}
public override void Visit(Token token)
{
sb.Append((string)token.Data);
sb.Append(" ");
}
}
var visitor = new SourceCodeVisitorLocal();
parserAsa.AST().Accept(visitor);
var source = visitor.Source;
Console.WriteLine(source);
Und das Ergebnis, wie nicht anders zu Erwarten:
select a , b , current date as c from dummy where 1 = 1
Die Klasse SqlAnsi2003QueryGrammarAsaParserVisitor ist eine Basisklasse, die für die verwendete Grammatik generiert wurde und für alle infrage kommenden Knotentypen Standardmethoden zur Verfügung stellt, die in unserer Ableitung überschrieben werden können. Da alle Knotenklassen die Methode Accept implementieren, brauchen wir uns nicht um die Navigation im Baum zu kümmern; das erledigen die Basisklassen selbst. Wir überschreiben hier die Visit(Token)-Methoden und fügen dem StringBuilder einfach den Inhalt der Data-Eigenschaft hinzu, plus ein Leerzeichen. In der Ausgabe sehen wir unseren Eingabetext, allerdings bereinigt um jegliche überflüssige Zeichen (sogenannte Whitespaces).
AST manipulieren
Wir wollen SQL Anywhere-spezifische Syntax übersetzen, sodass wir einen Befehl erhalten, der sich auch auf dem MS SQL Server ausführen lässt. In unserem einfachen Beispiel bedeutet die Verwendung von current date ein Problem, da diese spezielle ASA-Variable auf dem MS SQL Server nicht existiert. Also müssen wir diese ersetzen (zum Beispiel durch GetDate()). Dazu schauen wir zunächst in unseren Graphen und suchen den Knoten, der dieses Token repräsentiert (current date): generalvaluespecification11. Nun bauen wir einen Visitor, der genau diesen Knoten manipuliert und geben anschließend den Code für den Baum aus.
using AppFact.GoldParser.Interfaces.Interfaces;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa;
using AppFact.GoldParser.Engine;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.VisitorInterface;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Visitor;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Grammar;
public class ChangeCurrentDateVisitor : SqlAnsi2003QueryGrammarAsaParserVisitor
{
public override void PreVisit(generalvaluespecification11 astNode)
{
astNode.operand0.Data = "GetDate()";
}
}
var ast = parserAsa.AST();
var changeCurrentDateVisitor = new ChangeCurrentDateVisitor();
ast.Accept(changeCurrentDateVisitor);
var sourceCodeVisitor = new SourceCodeVisitorLocal();
ast.Accept(sourceCodeVisitor);
Consoel.WriteLine(sourceCodeVisitor.Source);
Die zugehörige Ausgabe:
select a , b , GetDate() as c from dummy where 1 = 1
Wir haben erfolgreich den AST dazu genutzt, eine vom MS SQL Server akzeptierte Anweisung zu erzeugen. Naja, nur fast, denn das FROM dummy quittiert der MS SQL Server mit einer Fehlermeldung, weil er die Tabelle dummy nicht kennt. Doch dazu später mehr, wenn wir umfangreichere Manipulationen vornehmen.
Komplexere Manipulationen
Der gesamte Prozess ist darauf ausgelegt, den AST so zu überarbeiten, dass am Ende aus jedem Stück SQL Anywhere-Sourcecode ein kompatibles Gegenstück für den MS SQL Server erzeugt wird. Das erfordert an einigen Stellen tiefere Eingriffe als die oben durchgeführte einfache Ersetzung von Tokens. Prinzipiell bleibt der Baum während der gesamten Zeit in seiner Struktur unverändert; wir überschreiben lediglich Tokens, fügen Anweisungen hinzu oder manipulieren den Generierungsprozess, indem wir im SourceCodeVisitor alternative Wege der Generierung beschreiten. In unseren Packages – Sie ahnen es bereits – gibt es eine Menge vordefinierter Visitoren. Insbesondere einen SourceCodeVisitor (der sich hinter der oben erwähnten Methode Source() verbirgt). Der SourceCodeVisitor macht sich einige Eigenschaften der Knotenbasisklassen zunutze, auf die wir im Folgenden etwas näher eingehen.
Wie oben angedeutet, macht ein FROM dummy auf dem MS SQL Server keinen Sinn. Sorgen wir also dafür, dass dies nicht mehr mit generiert wird.
using AppFact.GoldParser.Interfaces.Interfaces;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa;
using AppFact.GoldParser.Engine;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.VisitorInterface;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Visitor;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Grammar;
using Migrate.Common.Visitors;
public class ChangeFromDummyVisitor : SqlAnsi2003QueryGrammarAsaParserVisitor
{
public override void PreVisit(fromclause0 astNode)
{
// Wir wollen dafür sorfen, das die komplette from clause nicht mehr generiert wird.
// Da astNode an dieser Stelle aber kein Token ist, können wir nicht einfach den Token löschen.
astNode.CodeOverride = "/* gelöscht */ ";
}
}
var ast = parserAsa.AST();
var changeFromDummyVisitor = new ChangeFromDummyVisitor();
ast.Accept(changeFromDummyVisitor);
var sourceCodeVisitor = new SourceCodeVisitor();
ast.Accept(sourceCodeVisitor);
Console.WriteLine(sourceCodeVisitor.Source);
Mit folgenden Ergebnis:
select a , b , GetDate() as c /* gelöscht */ where 1 = 1
Wir haben die FROM-Klausel erfolgreich durch unseren Kommentar ersetzt. Gehen wir einen Schritt weiter und überschreiben die Generierung des gesamten Statements. In diesem Fall machen wir uns eine weitere Eigenschaft zunutze. Anstatt mit einem einzelnen String zu überschreiben, nutzen wir diesmal eine Liste von Objekten, Erklärung folgt.
using AppFact.GoldParser.Interfaces.Interfaces;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa;
using AppFact.GoldParser.Engine;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.VisitorInterface;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Visitor;
using AppFact.GoldParser.SqlAnsi2003QueryGrammarAsa.Grammar;
using Migrate.Common.Helper;
public class OverWriteStatementVisitor : SqlAnsi2003QueryGrammarAsaParserVisitor
{
public override void PreVisit(selectstatementcore1 astNode)
{
// Wir überschreiben die koplette Generierung.
// Die Teile die wir erhalten wollen stellen wir als Referenz an der gewünschten Position in CodeOverrides ein.
astNode.CodeOverrides = new List<object>(){
"SELECT "
, astNode.operand1
};
}
}
var ast = parserAsa.AST();
var overWriteStatementVisitor = new OverWriteStatementVisitor();
ast.Accept(overWriteStatementVisitor);
var sourceCodeVisitor = new SourceCodeVisitor();
ast.Accept(sourceCodeVisitor);
Console.WriteLine(sourceCodeVisitor.Source);
Betrachten wir das Ergebnis:
SELECT a , b , GetDate() as c
Q.E.D., wir haben die Generierung komplett überschrieben. Dazu ist noch anzumerken, dass wir die zu erhaltenden Teile per Referenz weitergeben, da unter Umständen noch weitere Visitoren folgen, die die ursprünglichen Knoten und Tokens verändern. Bei der endgültigen Generierung möchten wir natürlich sicherstellen, dass alle Transformationen berücksichtigt werden.
Fazit so far
Durch das Parsen und dem daraus resultierenden AST sind wir in der Lage, den Baum zu untersuchen und gezielt Teile zu ersetzen. Die Manipulationsfähigkeit reicht bis hin zum kompletten Überschreiben von zu generierendem Code. Hinzu kommt die Möglichkeit – die wir hier noch nicht gezeigt haben –, Generierungscode vor oder nach einem Knoten einzufügen. Das werden wir später auf jeden Fall brauchen, da uns Situationen begegnen werden, in denen wir nicht umhinkommen, zusätzliche Anweisungen zu erzeugen.
Die anderen Entitätstypen, wie Function, Procedure und Trigger, können auf ähnliche Weise bearbeitet werden. Naturgemäß kommen dabei andere Herausforderungen dauf uns zu, aber eine einzelne Behandlung an dieser Stelle würde den Rahmen sprengen.