Von SQL Anywhere zu Microsoft SQL Server Part I : DB-Schema und Datenübertragung
Wir haben also ein neues Projekt, die Migration einer SQL Anywhere (ASA) Datenbank nach Microsoft Sql Server… Ein Unterfangen, welches einiges an Arbeit erfordert und nur schrittweise erfolgen kann (warum werden wir noch sehen). Hier eine kurze Übersicht der Schritte, die wir in diesem Artikel beleuchten werden:
- Export des Datenbankschemas
- Teil-Erzeugung der Datenbank auf dem MS Sql Server
- Übernahmne der Daten aus der ASA Datenbank
- Erzeugen der Indices und Constraints
- Exportieren der Code Entitäten aus der ASA-DB
In jedem dieser Schritte werden wir auf erwartete und unerwartete Probleme stoßen. Jedes Mal sollten wir uns dann fragen, ob es möglicherweise Sinn macht, das Problem bereits in der ASA-DB zu lösen und den Prozess erneut laufen zu lassen. Wir sollten also unsere Projektorganisation darauf auslegen, dass die Migration ein iterativer Prozess ist und wir mehr als einen Durchlauf brauchen werden.
Export des Datenbankschemas
Die meisten Datenbanksysteme bieten die Möglichkeit, das DB-Schema (ggf. auch die Daten) in ein SQL-Skript zu exportieren. Das ist vielfach recht nützlich, aber aufgrund der Unterschiede der verschiedenen Systeme nicht besonders zielführend. Man wäre nach dem Export gezwungen, die Skript-Datei manuell zu überarbeiten. Das widerspricht natürlich dem iterativen Ansatz, bei dem wir Änderungen nach Möglichkeit nur automatisch oder am Anfang der Kette vornehmen wollen. Eine weitere Komplexität entsteht, wenn wir ein anderes Zielsystem anvisieren (Oracle, MariaDB, PostgreSQL, MySQL, …). Wir haben uns dazu entschieden, die Metadaten der ASA-DB in ein datenbankunabhängiges Format zu exportieren. In unserem Fall ist das XML, welches auf einem C#-Objektmodell basiert und damit sehr einfach zu serialisieren und deserialisieren ist. Letzteres wird im Laufe des Prozesses sehr handlich, weil wir (so viel nehme ich schon mal vorweg) immer wieder auf die Daten dieses Objektmodells zurückgreifen werden. Wir wollen so viel wie möglich autark erledigen und unnötige Zugriffe auf die ASA-DB vermeiden.
Wie kommen wir jetzt an die notwendigen Informationen?
Eine Möglichkeit ist natürlich, die entsprechende Dokumentation zu wälzen und zu recherchieren, welche System-Tabellen/Views und Prozeduren existieren, um die benötigte Information zu bekommen. Mühsam, sehr mühsam, zumal oft die Views bzw. Tabellen mit anderen Views und Tabellen gejoint werden müssen. Ein ziemliches Fass ohne Boden. Mit einem kleinen Trick kommen wir aber einfach an die benötigten Statements. Tools wie SQL Central machen ja auch nichts anderes, als die DB nach den benötigten Informationen zu befragen. Wenn wir die Möglichkeit hätten, die von Central ausgeführten SQL-Befehle mitzuschneiden, bekämen wir die benötigten Anfragen frei Haus geliefert. Seit ein paar Versionen gehört zur ASA-Installation ein Tool namens SQL Anywhere Profiler, welches hier sehr nützlich ist. Zur Verdeutlichung folgt hier ein Beispiel.
Wir möchten ermitteln welche Views auf unserer ASA-DB existieren. Dazu gehen wir wie folgt vor:
- DB starten
- Sybase Central aufrufen und sich mit der DB verbinden (nichts weiter tun!)
- Auf dem DB-Knoten in Central mit der rechten Maustaste das Kontextmenü und die Option „Interactive SQL öffnen“ wählen
- In ISQL über den Menüpunkt „Extras“ den SQL Anywhere Profiler starten
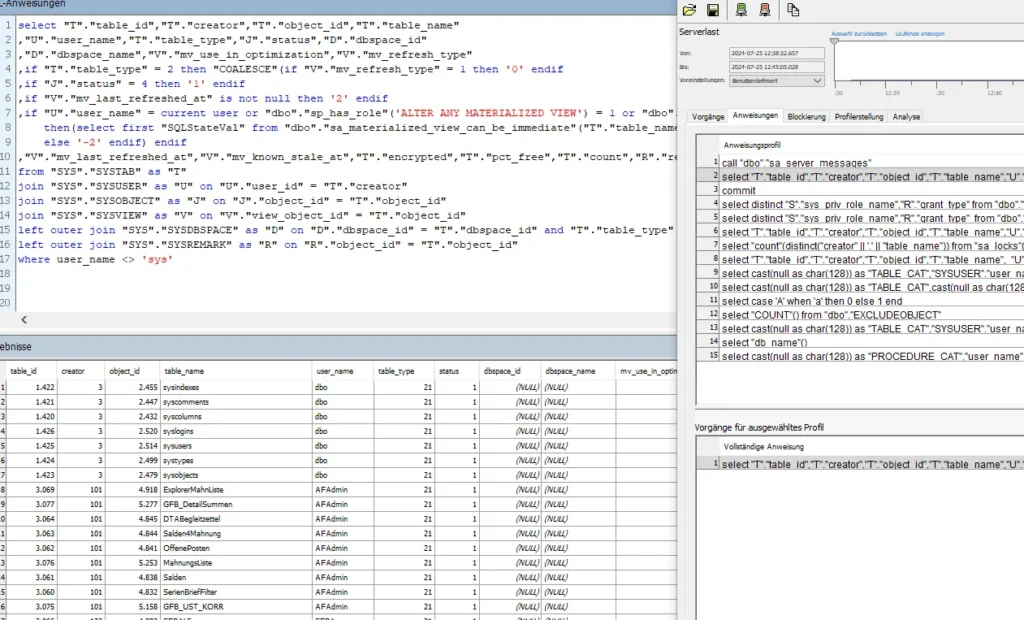
In dem Screenshot sehen Sie, wie ich aus dem Profiler das von Central ausgeführte Statement kopiert habe und es in ISQL ausgeführt habe. Et voilà, wir haben eine Liste der Views mit den benötigten Informationen.
Auf die gleiche Art und Weise können wir uns Statements für alle benötigten Informationen beschaffen: Tabellen, Spalten, Indices, Constraints, Domains, Procedures, Functions etc. pp.
Sollten wir zu einem späteren Zeitpunkt mal eine DB von einem anderen DB-System migrieren wollen (z.B. MSSQL -> Postgres), wäre es ein Leichtes, entsprechende Statements für ein anderes System zu schreiben, die entsprechende Resultsets zurückgeben.
Jetzt noch schnell ein Objektmodell definiert, das könnte z.B. so aussehen:
[DataContract(Namespace = "", Name = "databaseschema")]
public class DatabaseSchema : DatabaseObject
{
...
#region Properties
[DataMember(Name = "tables", EmitDefaultValue = true, Order = 5)]
[Browsable(true)]
public DatabaseTableCollection Tables
...
[DataMember(Name = "views", EmitDefaultValue = true, Order = 6)]
[Browsable(true)]
public DatabaseViewCollection Views
...
[DataMember(Name = "procedures", EmitDefaultValue = true, Order = 7)]
[Browsable(true)]
public DatabaseProcedureCollection Procedures
...
[DataMember(Name = "userdefinedtypes", EmitDefaultValue = true, Order = 7)]
[Browsable(true)]
public DatabaseUserDefinedTypeCollection UserDefinedTypes
...
#endregion
...
}
Es geht an dieser Stelle nur ums Prinzip, deshalb erspare ich Ihnen die Implementierungsdetails. Wir nehmen also unsere Statements und füllen eine Instanz der Klasse DatabaseSchema. Wir können dann mit einer Zeile Code die Definition auf eine XML-Datei speichern. Später werden wir dann diese Definition wieder laden, um daraus Informationen für das weitere Vorgehen abzuleiten.
Teil-Erzeugung der Datenbank auf dem MSSQL Server
Warum nur eine Teilerzeugung?
Nun, um später die Daten übernehmen zu können, müssen wir das Schema in Schritten aufbauen. Im initialen Laden der neu zu erzeugenden DB dürfen einige Dinge noch nicht aktiv sein. Beispielsweise sind alle Operationen zu vermeiden, die die Daten ändern würden (Beispiel Trigger), denn diese sind auf dem Quellsystem ausgeführt worden.
Im ersten Schritt geht es also erstmal nur darum, alle Tabellen mit ihren Spalten und notwendigen Primary Keys anzulegen. All diese Informationen haben wir ja in unserer XML-Datei, also laden wir diese und generieren die für das Zielsystem notwendigen SQL-Befehle. Bei uns hat es sich bewährt, diese Statements direkt gegen das Zielsystem auszuführen und eventuelle Fehler bzw. Warnings in ein Log zu schreiben. Hier sollte man auch wiederum bedenken, dass man ggf. für verschiedene Zielsysteme generieren möchte, also sollte man das Beschaffen der notwendigen Statements hinter einem Interface verstecken. Das könnte z.B. so aussehen:
/// <summary>
/// This Interface encapsulates the specific implementations for different SQL dialects
/// </summary>
public interface IStatementGenerator
{
string CreateDatabase(string databaseName);
string CreateSchema(string schemaName);
string CreateTable(DatabaseTable table);
string CreateIndexes(DatabaseTable table);
string CreateForeignKeys(DatabaseTable table);
string CreateTableConstraint(DatabaseTable table);
string CreateView(DatabaseView view);
string CreateProcedure(DatabaseProcedure procedure);
string CreateUserDefinedType(DatabaseUserDefinedType userDefinedType, DatabaseProcedureCollection procedures);
string CreateFunctionStub(DatabaseProcedure procedure, bool withGo);
string CreateCheckConstraintsOnColumn(DatabaseTable table, DatabaseColumn column, DatabaseProcedureCollection procedures, bool withGo);
string CreateDefault(DatabaseTable table, DatabaseColumn column, DatabaseProcedureCollection procedures);
}
Wir verwenden hier natürlich die im Objektmodell definierten Klassen. Da diese bereits DB-unabhängig sind, haben wir uns an dieser Stelle die weitere Abstraktion über Interfaces gespart. Für jedes gewünschte Zielsystem implementieren wir jetzt eine Klasse, die dieses Interface umsetzt. In unserem Beispiel:
/// <summary>
/// Statement Generator for MS SQL Server dialect
/// </summary>
public class MsSqlStatementGenerator : IStatementGenerator
{
...
}
Auf diese Art und Weise haben wir uns sehr elegant von verschiedenen Inkompatibilitäten gelöst. So könnten wir im Generator beispielsweise bestimmte Datentypen automatisch auf andere Datentypen mappen. So bedeutet der Datentyp „TimeStamp“ auf der ASA etwas komplett anderes als auf der MSSQL.
Mit welchen Problemen müssen wir rechnen?
- Datentypen sind nicht zu 100% kompatibel
- Auf der MSSQL-Seite stoßen wir auf Limitierungen (Recordgröße)
- Primary Key Violations aufgrund unterschiedlcher Handhabung von Trailing Blanks
- Primary Key Definitionen auf Spalten, die auf der MSSQL-Seite nicht als PK-Spalten zugelassen sind (varchar(max))
- Tabellen ohne PK … more to come
Die letzten drei Punkte sind ein Beispiel dafür, dass wir das am Ursprung fixen sollten.
Übernahme der Daten aus der ASA Datenbank

Um die Daten zu übernehmen, stehen uns mehrere Wege zur Verfügung:
- Export der Daten als Insert-Statements in eine Script-Datei und Ausführung dieser Script-Datei auf der Ziel-DB (die ja jetzt existiert)
- Eigenes Tool, welches über ADO.Net Datatables bildet und auf dem Zielsystem einfügt
- Serverside-Mechanismen nutzen
Es kommt ein wenig darauf an, welche Umgebungen und Ressourcen zur Verfügung stehen, um sich für ein Vorgehen zu entscheiden. Gegen eine Scriptdatei spricht, dass die Logging-Möglichkeiten nur sehr eingeschränkt zur Verfügung stehen. Der Weg über ADO.Net und Datatables hat den Nachteil, dass bei sehr großen Datenbeständen es leicht zu Problemen mit der Speichernutzung kommen kann, welches dann wiederum erfordert, dass man erhöhten Aufwand für das Management solcher Datenmengen betreiben muss. In unserem Fall setzen wir auf die Kombination aus ADO.Net und serverside Mechanismen.
Die MSSQL bietet die Möglichkeit, sogenannte Linked Server zu definieren. Im Falle einer ASA 17 Installation auf der gleichen Maschine (wie der MSSQL) steht ein Treiber zur Verfügung (SQL Anywhere OLE DB Provider 17), über den ein Linked Server definiert werden kann. Über diesen kann man dann serverseitig auf die ASA zugreifen.
Aus unserem Objektmodell kennen wir ja alle Tables, damit lassen sich die Daten sehr einfach übernehmen. Definieren wir folgendes Template:
insert into {@table} (*) select * from OPENQUERY({@database}_LINKED,'select * from {@table}');
{@database}_LINKED ist hierbei unsere Namenskonvention für den Namen des Linked Servers. Jetzt können wir ADO.Net nutzen, um dem Server die Anweisung zu erteilen, die Daten aus der Quelle zu übernehmen. Hier ein wenig Pseudocode:
public void Transferdata()
{
...
// Schema ist das aus der XML geladene Objektmodell
foreach (var table in Schema.Tables)
{
var stmtTemplate = "insert into {@table} (*) select * from OPENQUERY({@database}_LINKED,'select * from {@table}');";
var columns = table.Columns.Select(c => "[" + c.Name + "]").ToList();
var columnList = string.Join(", ", columns);
stmtTemplate = stmtTemplate.Replace("*", columnList);
var tableFqn = $"[{table.Owner}].[{table.Name}]";
stmtTemplate = stmtTemplate.Replace("{@table}", tableFqn);
stmtTemplate = stmtTemplate.Replace("{@database}", Schema.FullName);
if (!ExecuteStatement(stmtTemplate, true))
{
...
}
...
}
}
Das Ganze geht deshalb so einfach, weil die Strukturen ja identisch sind. Durch die Ausführung über den Server haben wir den Vorteil, dass die Konvertierungen, falls nötig, automatisch erledigt werden. Unserer Feststellung nach ist diese Vorgehensweise nicht nur die schnellste, sondern auch die, die mit den Ressourcen am schonendsten umgeht. Und sie bietet uns einen recht großen Detailgrad beim Logging (überall, wo die … stehen, sind im Originalcode entsprechende Logging-Anweisungen).
Erzeugen der Indices, Constraints, Domains, Defaults

Nachdem wir jetzt die Daten auf dem Zielsystem haben, können wir uns den noch fehlenden Entitäten widmen. Ähnlich wie oben arbeiten wir uns durch das Objektmodell, lassen uns vom IStatementGenerator die entsprechenden Anweisungen generieren und führen diese gegen die Zieldatenbank aus. Allerdings stoßen wir hierbei auf ein Problem. Index-Definitionen, Constraints und Defaults können u.U. auf Funktionen verweisen, die wir aber erst später dem System hinzufügen werden. Um trotzdem diesen Schritt durchführen zu können (es geht im Wesentlichen darum, Probleme zu erkennen), erzeugen wir für alle Funktionen Dummys. Wir erzeugen die richtige Signatur, nur lassen wir die Funktionsbodies leer. Damit sind wir gerüstet und bestenfalls lassen sich alle fehlenden Entitäten erzeugen.
Natürlich sind die tatsächlichen Indexinformationen u.U. noch nicht vollständig (wegen der fehlenden Funktionsimplementierung), deshalb müssen ganz am Ende des Prozesses die Indices nochmal neu erzeugt werden.
Auch in diesem Abschnitt ist wieder mit Problemen zu rechnen:
- Index-Definition auf Spalten, die nicht für einen Index zulässig sind (varchar(max))
- Foreign Key Definition mit unvollständigen Angaben
- Cascading-Einstellungen, die auf MSSQL zu Warnings führen
- … and more
Exportieren der Code Entitäten aus der ASA-DB
Wir haben jetzt schon mal eine DB, die eine vollständige Kopie der Daten aus der Ursprungsdatenbank enthält. Zur Funktionsfähigkeit fehlen noch die Code-Entitäten: Views, Functions, Procedures, Triggers. Als Vorbereitung des nächsten Schrittes holen wir noch den Sourcecode für diese Entitäten auf die Platte. Technisch kein großes Problem mehr, da wir beim Erzeugen unseres Objektmodells natürlich dafür gesorgt haben, dass der Sourcecode bereits im Modell vorhanden ist. Jetzt schreiben wir diesen in einzelne Dateien auf die Platte in eine vordefinierte Ordnerstruktur. Bei mir sieht diese wie folgt aus:
.\Code
-- View
-- Function
-- Procedure
-- Trigger
Soweit die Vorbereitungen für den nächsten Schritt, in dem es eigentlich erst so richtig losgeht, denn dann fangen wir an, Sourcecode zu migrieren.